1.storm简介
a:storm是一个开源免费的分布式实时计算系统,它可以轻松的处理无界的数据流。
b:storm只负责数据的计算,不负责数据的存储。
2.storm应用场景
实习计算,在线机器学习,连续计算,分布式RPC,ETL等。
3.storm的核心技术组成
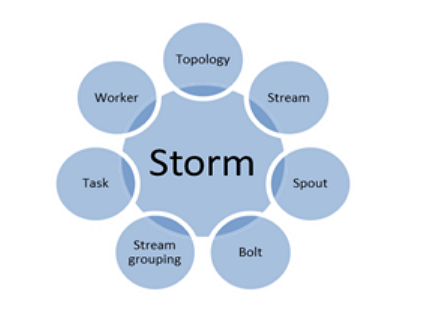
a:Topology(拓扑)
一个拓扑是一个图的计算,一个拓扑是由若干个Spout,Bolt组成
b:Stream(流)
流式storm的核心抽象,一个流是一个无界Tuple序列,Tuple可以包含整型,长整型,短整型,字节,字符,双精度数,浮点数,布尔值和字节数组。
c:Spout
spout是Topology流的数据来源。一般Spout从外部来源读取Tuple,然后提交到Topology。
d:Bolt
Topology中的所有数据的处理都是在Bolt中完成的。Bolt可以完成数据过滤,业务处理,连接运算,连接,访问数据库等操作。
e:Stream grouping(流分组)
流分组在Bolt的任务中定义流应该如何分区。
f:Task(任务)
每个Spout或Bolt在集群中执行许多任务,每个任务对应一个线程的执行。
3.集群架构
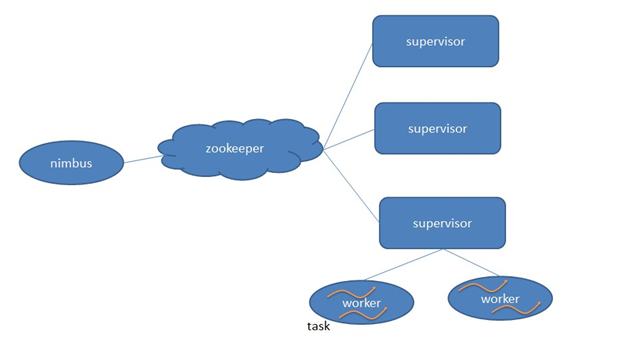
Nimbus:负责资源分配和任务调度
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的Worker进程。
Task:worker中每一个spout/bolt的线程称为一个task。
流程:
a:在集群架构中,用户提交到任务到storm,交由nimbus处理。
b:nimbus通过zookeeper进行查找supervisor的情况,然后选择supervisor进行执行任务。
c:supervisor会启动一个work进程,在worker进程中启动线程进行执行具体的业务逻辑。
4.工作进程,执行器,任务之间的关系
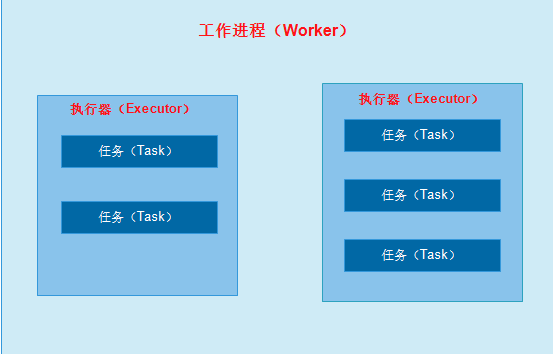
a:工作进程(worker):在storm中,所提交的Topology将会在supervisor服务器上启动独立的进程来执行。
b:执行器(executor):是在worker中执行的线程,在向Topology添加spout或bolt时可以设置线程数。
d:任务(task):是在执行器中最小的工作单元。
在默认的情况下task和executor的 数量是一样的,也就是说,默认情况下storm会在每个线程上运行一个task。